Overview
The Skinny
In this blog post, we explore the correct way to implement bi-directional Tungsten Replication between AWS Aurora and Tungsten Clustering for MySQL databases.
Background
The Story
When we are approached by a prospect interested in using our solutions, we are proud of our pre-sales process by which that we engage at a very deep technical level to ensure the we provide the best possible solution to meet with the prospect’s requirements. This involves an in-depth hands-on POC, in addition to the significant time and effort we spend building and testing the solution architectures in our lab environment as part of the proposal process.
From time to time, we are presented with requirements that are not always quite so straight forward. Just recently we faced such a situation. A prospect that is currently a heavy Amazon Aurora user is interested in converting to a Tungsten Composite MultiMaster solution, across multiple regions both in Amazon and across Google Cloud. This is quite a common request as customers realise that whilst Amazon Aurora does have many benefits, there are many occasions where it falls short.
The basic requirement to convert from Aurora to Tungsten Clustering is normally straight-forward and is something we have done on many occasions, so no issue there.
Next, cross-cloud replication is one of our strengths – the ability to have instance-based clusters in both Amazon Web Services and in Google Cloud Platform, all replicating to each other – this is one of our many unique selling points.
What made this requirement a little more challenging was the need to be able to provide bi-directional replication between Aurora and the new Tungsten clusters. This was to be a temporary solution to allow the business to migrate and test the applications, and also provide an easy rollback should any issues arise.
So why was this challenging? Surely if we provide MultiMaster clustering, then this should be a no-brainer, right? Well, not quite.
When we replicate, we extract transactions from the MySQL binary logs. If we replicate bi-directionally, we need to be sure that we do not create a circular replication loop by re-applying events we just sent to the other side.
When we do this between native (non-RDS/Aurora) MySQL sources and targets, the cross-cluster replicator can control this by bypassing the writes to the binary logs for transactions that the replicator applies.
With Amazon Aurora (and RDS) it’s not possible to bypass this step, because `set session sql_log_bin=0` simply isn’t allowed. While there are perfectly valid reasons for this (i.e. you are using replicas), this means that with a default install for our Tungsten Replicator, a change made to the Tungsten-managed databases would replicate to Aurora (Good), hit the binlog in Aurora and then be replicated back (Bad).
OK, so that’s the background covered, let’s take a look at how we can resolve this. Fortunately, Tungsten Replicator is both extremely configurable and powerful, and so actually resolving this challenge was pretty straight-forward – it just required a few careful steps, a bit of testing, and a good understanding of all of the various properties!
Procedure Summary
Understand the Steps First
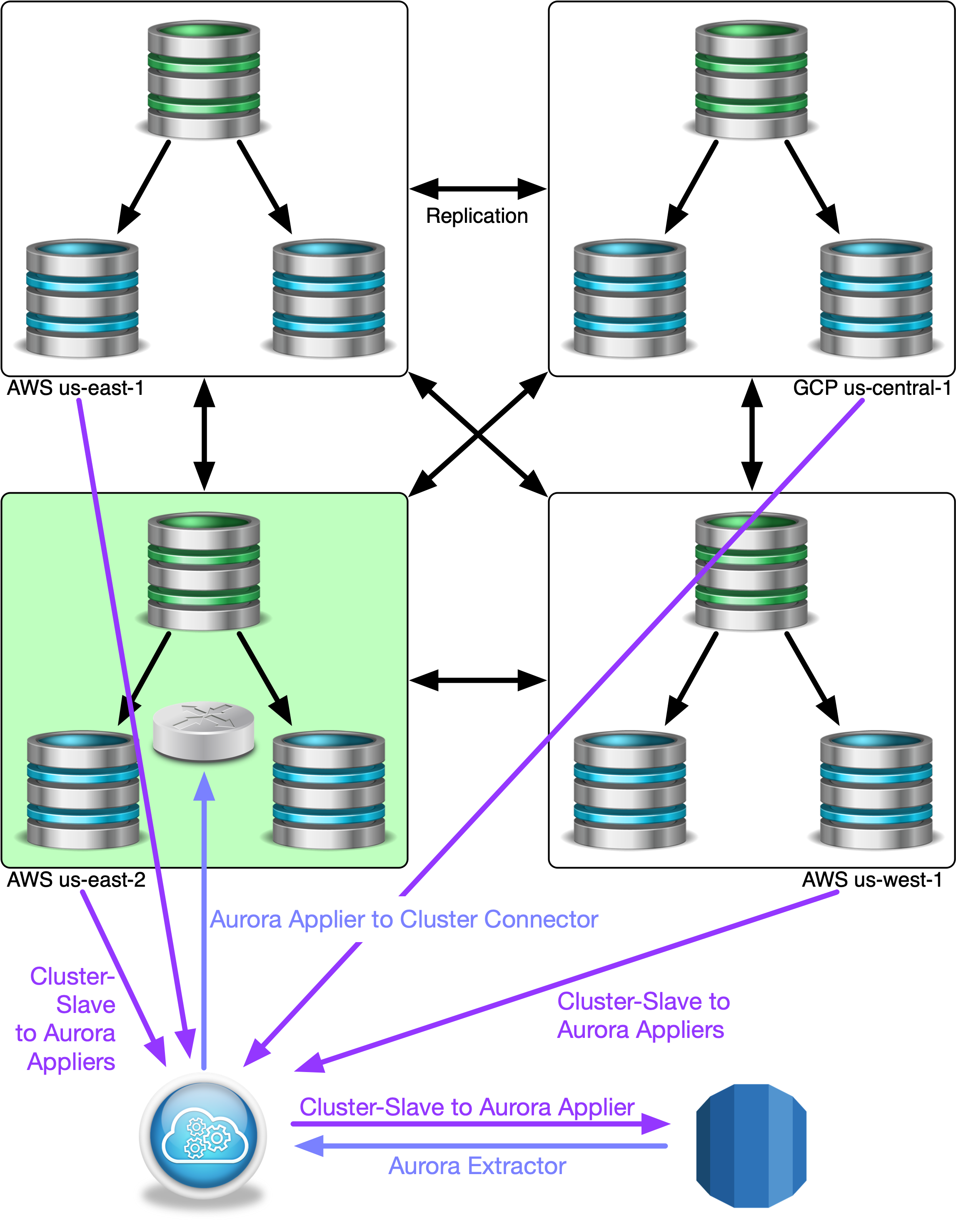
This is what is needed to create bi-directional Tungsten replication streams between AWS Aurora and one or more Tungsten Clusters:
From Aurora to the Cluster(s)
- Aurora Extractor - An extractor configured to read from Aurora
- Aurora Applier to Cluster Connector - A single applier that would write the Aurora changes, via a connector into the one cluster only
From the Cluster(s) back to Aurora
- Cluster Config Change - A single change to every cluster’s config to provide the replicators a little bit of extra detail
- Configure Cluster-slave(s) - A single Cluster-Slave for EACH Tungsten cluster to replicate changes back to Aurora
Procedure Details
In the Weeds
-
Aurora Extractor
This is a fairly straight forward configuration, the extractor is configured in the same way as any regular standalone MySQL extractor, but with two very important additional parameters:
svc-extractor-filters=dropcatalogdata property=replicator.service.comments=trueThe first is a filter that ensures the tracking schema doesn’t replicate because normally the creation of this would bypass binary logs – we don’t want this replicating!!
The second ensures that any transaction we extract from the local binary logs is tagged with the name of the service that the extractor is running, in my case I called my service aws2cluster
-
Aurora Applier to Cluster Connector
Again, this is a fairly simple and straight forward applier service. First of all, we configure this applier to write to a connector, this will mean that we can have a single applier that doesn’t need to be tied to the master in the cluster, by going through the connector we know we will always reach the master but would never need to reconfigure if the master switched.
Additionally, we include the following properties:
property=local.service.name=localcluster property=replicator.service.type=remote svc-applier-filters=bidiSlave log-slave-updates=trueThe first, local.service.name sets a service that we associate with our target – The replicator uses this to stop transactions being applied if they are tagged with a service name that is anything other than the servicename the replicator is running as, so in this case it is ensuring we only apply transactions tagged with “aws2cluster” as the OriginatingService
On its own, this property won’t do a lot, but when it’s combined with the next two properties – service.type=remote and the bidiSlave filter – that’s when the replicator starts to get interesting.
Finally, log-slave-updates will ensure that anything this replicator writes, goes into the binary log of the master, so that this then propagates to all of the nodes in all the clusters.
-
Cluster Config Change
All the nodes in all the clusters also need one very small change – the addition of:
property=replicator.service.comments=trueLike the Aurora extractor, this ensures anything written in the local clusters are tagged with their service names.
-
Configure Cluster-Slave(s)
We now configure one or more cluster-slave replicators. There is a single replicator associated with each cluster, which will read THL generated by that cluster and apply it back to the Aurora instance. This configuration also has the same additional properties as the applier into the cluster, specifically:
property=local.service.name=aws2cluster property=replicator.service.type=remote svc-applier-filters=bidiSlave
So let’s take a quick look at what this does to THL
Insert into AWS that we want to replicate – Note the source id and service tag:
MyService = aws2cluster
OriginatingService = aws2cluster
TargetLocalService = localcluster
Result = APPLY
SEQ# = 100 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2019-09-08 11:48:31.0
- EPOCH# = 0
- EVENTID = mysql-bin-changelog.000002:0000000000143042;-1
- SOURCEID = p28test.cluster-cw8gilzabv20.eu-west-1.rds.amazonaws.com
- METADATA = [mysql_server_id=1395894048;dbms_type=mysql;tz_aware=true;service=aws2cluster;shard=demo]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(0) =
- ACTION = INSERT
- SCHEMA = demo
This means this will replicate, via the connector into the cluster, but because of log-slave-updates to ensure all the nodes in the cluster are updated, this ends up being picked up by the cluster-slaves but because the servicename is different, it won’t get replicated back.
Now, insert into a cluster node that we want to replicate to Aurora, again note Source ID and service:
MyService = nyc
OriginatingService = nyc
TargetLocalService = aws2cluster
Result = APPLY
SEQ# = 52 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2019-09-08 11:52:33.0
- EPOCH# = 42
- EVENTID = mysql-bin.000002:0000000000031207;-1
- SOURCEID = db1
- METADATA = [mysql_server_id=940;dbms_type=mysql;tz_aware=true;service=nyc;shard=demo]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = ISO-8859-1]
- SQL(0) =
- ACTION = INSERT
- SCHEMA = demo
- TABLE = regions
Because we can’t bypass writing to Aurora binlogs, this ends up being extracted again, but because of the servicename being different to the servicename of the extractor process itself, and the bidiSlave filter on the applier, we know that this is something that came in from another Master and therefore we discard it:
MyService = aws2cluster
OriginatingService = nyc
TargetLocalService = localcluster
Result = DISCARD
SEQ# = 101 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2019-09-08 10:59:08.0
- EPOCH# = 0
- EVENTID = mysql-bin-changelog.000002:0000000000143935;-1
- SOURCEID = p28test.cluster-cw8gilzabv20.eu-west-1.rds.amazonaws.com
- METADATA = [mysql_server_id=1395894048;dbms_type=mysql;tz_aware=true;is_metadata=true;service=nyc;shard=demo]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(0) =
- ACTION = INSERT
- SCHEMA = demo
- TABLE = regions
So there we go, by using some of the more advanced features of the replicator we can safely setup bi-directional replication between Aurora and a Tungsten Cluster
The Library
Please read the docs!
For more information about Tungsten clusters, please visit https://docs.continuent.com
Summary
The Wrap-Up
In this blog post we discussed the correct way to implement bi-directional Tungsten Replication between AWS Aurora and Tungsten Clustering for MySQL databases.
Tungsten Clustering is the most flexible, performant global database layer available today – use it underlying your SaaS offering as a strong base upon which to grow your worldwide business!
For more information, please visit https://www.continuent.com/solutions
Want to learn more or run a POC? Contact us.

Comments
Add new comment