Introduction
Tungsten Clustering is a powerful tool with many moving parts, including the Tungsten Connectors which may be installed on any application server.
During a troubleshooting event, it is helpful to understand what to look for and where, in addition to understanding how the logs work together to provide a clear picture of the situation.
In Tungsten version 7, we introduced a number of features designed to make troubleshooting easier.
In this blog post, we will cover the basic three log files (trepsvc.log, tmsvc.log and connector.log) and the relationships between them. We will also explore the new commands and log files in version 7.
The Puzzle - What Are The Moving Parts?
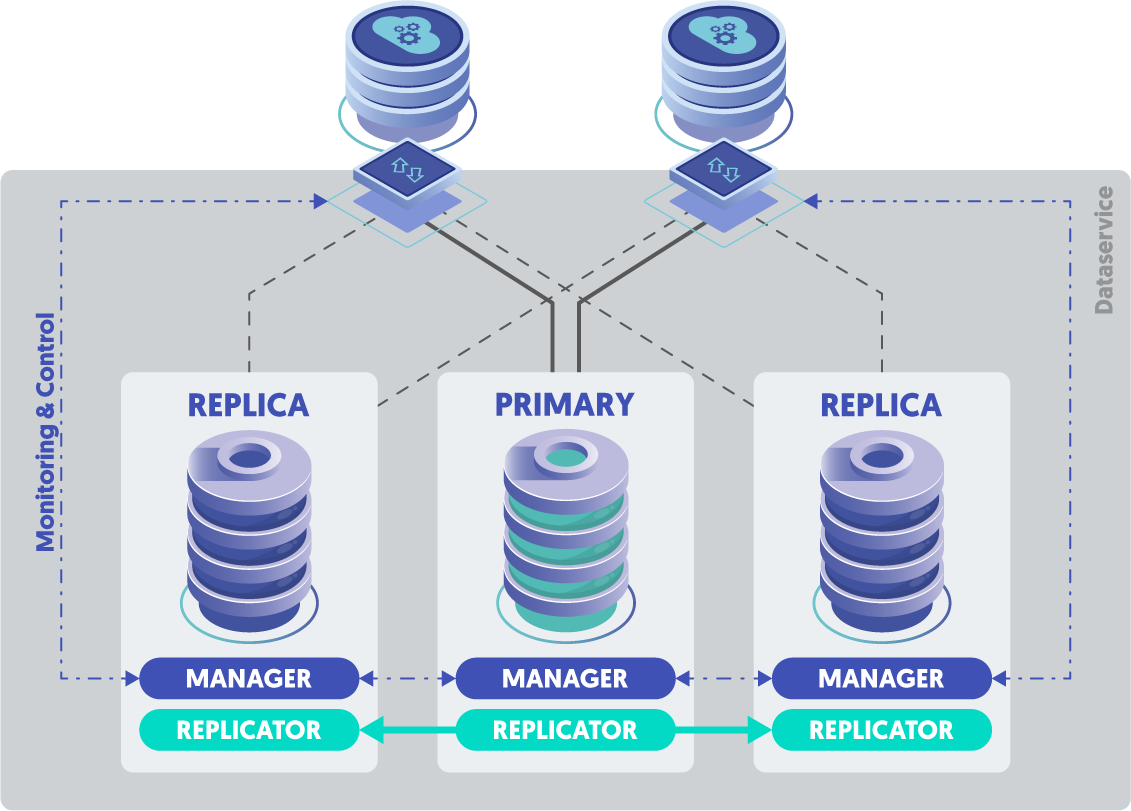
Tungsten Connector - Intelligent Proxy
Connectors are the intelligent proxy that sits between the calling client application and the needed database server resources. They route traffic based on the state of the cluster, so the Connectors need to know which local database node is the writable Primary, and which local nodes are the Replicas, and for Composite clusters, they also need to know this same information about remote clusters.
Connectors must get this needed state information from one of the available local Managers, and will connect to the first manager that answers the broadcast. Once connected, the Connector will pull state information every three seconds from the Manager. This state information is used to control the flow of client traffic to the writable primary database node, and optionally to read-only replicas.
Tungsten Manager - Command and Control
The Manager also provides instructions and signals about events that influence the flow of client traffic.
For example, a Manager that loses quorum with the other Managers can tell a Connector to go ONHOLD, and suspend all new client requests for the database because the available cluster state information is no longer authoritative. The Connector ONHOLD will cause all new requests to hang, and the calling client will experience delays until the Connector gets a signal to go back ONLINE, either from the failing Manager, or by connecting to a different Manager that does have quorum, and therefore a valid cluster state. These Connector state changes are clearly reflected in the connector.log file, and the log entries will identify the associated Manager host.
Since the Connectors make routing decisions about the flow of client traffic based on the information and signals from the Managers, we can consider the Manager the Gate-Keepers, and the Connectors will open and close the gate based on instructions from the Manager layer.
Managers also have a significant relationship with each other, and that is reflected in the Manager’s log file, tmsvc.log. The most basic is the establishment of the voting Quorum via the Java Group Communications channel. One Manager is responsible for taking on the COORDINATOR role, which means that all decisions made by the quorum will be executed on the coordinator node, and the logs on that node will reflect the actions taken.
To view the current coordinator, use the cctrl command:
shell> echo ls | cctrl | grep COORD
COORDINATOR
You may also use the tpm ask coordinator command in v7.0.2 and greater:
shell> tpm ask coordinator
db9-demo.continuent.com
To properly troubleshoot any cluster-level problems, the tmsvc.log files from all of the database nodes need to be consulted in parallel, to check messages happening around the same time in different logs. By including the connector.log files as well, a clear picture of the cluster decisions and impacts can be obtained.
Tungsten Replicator - Data Mover
Key to Tungsten Clustering is the ability to move MySQL write events from the Primary to the Replicas. The Tungsten Replicator performs this function, which is also controlled by the Manager layer, although in a different way. During switch and failover actions, it is the Manager that instructs Replicators on various nodes to change roles and where to point to for needed THL resources. In the case of a Composite cluster, this coordination happens on all nodes on all clusters world-wide (as needed), automatically handling the replication layer reconfiguration with no inputs needed from a DBA.
The Manager layer issues commands to the Replicators through the Coordinator node once a quorum decision is made. That is why it is always good to read the tmsvc.log file on the Coordinator node first.
The Tungsten Replicator records these Manager instructions in the trepsvc.log file, along with all other Replicator diagnostic output.
Please note that if the current Coordinator Manager restarts, a new Coordinator will be elected, so it is quite possible for different nodes to be the Coordinator at different times, making the inspection of all the logs together essential.
Solving the Puzzle - Putting the Pieces Together
Since we must inspect all of the logs together to get the complete picture, having one place to view all of the logs together would make the troubleshooting process much easier. First, we must gather the information we need.
Tools of the Trade: tpm diag
The tpm diag command is the core tool used to gather all the needed information about a cluster for troubleshooting purposes.
The operation of tpm diag differs between installation types (Staging vs INI). This is outlined below:
- With Staging-method deployments, the
tpm diagcommand can be issued in two ways:- The
tpm diagcommand alone will obtain diagnostics from all hosts in the cluster. - The
tpm diag --hosts host1,host2,hostNcommand will obtain diagnostics from the specified host(s) only.
- The
- Within an INI installation, the behavior is:
- The
tpm diagcommand alone will ONLY obtain diagnostics from the local host on which the command is executed. - The
tpm diag --hosts host1,host2,hostNcommand will obtain diagnostics from the specified host(s) only. - The
tpm diag -a|--allhostscommand will attempt to obtain diagnostics from all hosts in the cluster if ssh has been configured and the other hosts can be reached. The output of tpm diag will provide feedback detailing the hosts that were reached.
- The
For more information, please see the online documentation: https://docs.continuent.com/tungsten-clustering-7.0/cmdline-tools-tpm-commands-diag.html
Tools of the Trade: tungsten_merge_logs
Once we have the logs via the diag, the next step is inspecting them as a unit. To this end, the tungsten_merge_logs command was created. This tool gathers the needed logs into a single file, sorted by timestamp, and marked by hostname, allowing for contextual inspection of the log lines. The command was designed to be used in conjunction with the `tpm diag –all` command, so that log files from all nodes are gathered into one place for merging. Certainly, log files may be gathered manually and placed into a subdirectory for consumption by the script.
With no options specified, the tungsten_merge_logs script will gather all log files in the current directory and below the current directory recursively. For example:
shell> cd
shell> tpm diag --allhosts
shell> tar xvzf tungsten-diag-2021-11-15-16-37-33.tgz
shell> cd tungsten-diag-2021-11-15-16-37-33
shell> tungsten_merge_logs
would result in something like the following:
New merged log file ./merged.log created!
Some operational guidelines for tungsten_merge_logs are:
- All logs files are gathered by default.
- If you specify any of --connector, --replicator, --manager or --cctrl, then only the log files for the specified components will be gathered.
- Using multiple options will aggregate the logs from the specified components.
- The output file (i.e. /home/tungsten/tungsten-diag-2021-11-15-16-37-33/merged.log) will be overwritten without warning if it exists.
As of v6.1.18 and v7.0.2, the tungsten_merge_logs command will support the --before and --after filters, which will exclude lines from the output based on a timestamp:
[--before {TIMESTAMP}] Discard all lines after {TIMESTAMP}
[--after {TIMESTAMP}] Discard all lines prior to {TIMESTAMP}
The {TIMESTAMP} must be specified as a single argument wrapped in quotes,
in the format of 'yyyy/mm/dd hh:mm:ss', including a single space between
the date and time. Hours are in 24-hour time, and all values should be
left-padded with zeros. For example:
tungsten_merge_logs --before '2021/09/27 21:58:02'
(Feature as of v6.1.18 and v7.0.2)
A previous blog post covers the tungsten_merge_logs command in detail: https://www.continuent.com/resources/blog/easier_log_analysis_tungsten_merge_logs
The Big Picture: Understanding Log Entries In Context
Once the lines are merged, it will be much easier to see lines from different hosts together, which will create a timeline of events that can be better understood.
New Logs in v7
As of version 7.0, there are some logging enhancements. First off, a new file, $CONTINUENT_ROOT/tungsten/tungsten-manager/logs/console.log, (and also sym-linked to in the $CONTINUENT_ROOT/service_logs directory) has been added which reflects all cctrl output on that node. This is in addition to the existing cctrl.log, which records all commands entered into cctrl on that node.
Also, the tungsten_find_orphaned tool now creates a log file in the $CONTINUENT_ROOT/service_logs directory to aid in troubleshooting issues where THL was left behind on an old Primary.
Wrap-Up
In this post we explored some of the key Tungsten troubleshooting log files and the relationship between them, including the new log files included with Tungsten version 7+.
For more information, please see our Continuent Blog and Docs:
- https://www.continuent.com/resources/blog/easier_log_analysis_tungsten_merge_logs
- https://docs.continuent.com/tungsten-clustering-7.0/cmdline-tools-tpm-commands-diag.html
Smooth sailing!

Comments
Add new comment