Enterprises require high availability for their business-critical applications. Even the smallest unplanned outage or even a planned maintenance operation can cause lost sales, productivity, and erode customer confidence. Additionally, updating and retrieving data needs to be robust to keep up with user demand.
Let’s take a look at how Tungsten Clustering helps enterprises keep their data available and globally scalable, and compare it to Amazon's RDS running MySQL (RDS/MySQL).
Replicas and Failover
What does RDS do?
Having multiple copies of a database is ideal for high availability. RDS/MySQL approaches this with “Multi-AZ” deployments. The term “Multi-AZ” here is a bit confusing, as enabling this simply means a single "failover replica" will be created in a different availability zone from the primary database instance. Only one failover replica can be created, and thus we have just one failover candidate with a copy of the database in a “Multi”-AZ deployment. The failover replica has only one purpose - to be used as a failover target, and cannot be used for other purposes – but more about this later.
The failover process for RDS happens automatically and takes between 1 – 2 minutes. It also updates the DNS record for the database to point to the failover replica. As a result, we have the following consequences:
- Application downtime of 1 -2 minutes
- Application must reconnect to database, which, depending on the application, may report cryptic errors to the user or even crash
- You may need to reconfigure your JVM environment to handle DNS caching in this case
- You now do not have any other failover candidates until another is brought online
How does Tungsten Clustering handle failover?
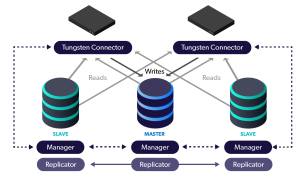
Using Tungsten Clustering, you set up your cluster to have a primary (master), and 2 or more replicas (slaves). Each slave in a cluster is a candidate for failover, and since this is a true cluster, the application simply connects to the cluster with no modification, and any changes to the cluster happen behind the scenes to the application. This is made possible using the Connector, which is an intelligent proxy that speaks the MySQL protocol.
During failover, the cluster selects a slave to promote to master. The Connector temporary holds connections from the applications until failover process is complete. When the slave has been promoted to master, the Connector resumes connections but to the new master. The advantages here are:
- Fast failover time, often within 10 seconds!
- Applications do not get disconnected. No errors reported to the users.
- Applications do not need to be aware of a new master
- After a failover in a 3 node cluster, there is still yet another slave that can handle a subsequent failover. A 5 node cluster with a failed master would still have 3 slaves online!
- The failed master in many cases can repaired and added back into the cluster, saving reprovisioning time.
Performance and Scalability
RDS Style
RDS/MySQL provides “read replicas,” which, although not automatic failover candidates, are replicas of the primary instance and can be used for reading data, offloading some traffic from the master. Note that a read replica can be manually promoted to a master. A read replica will have a different IP address, thus to take advantage of using it for reads, your application must be designed to send reads to the read replica, and writes to the master.
Coming back to the “failover replica,” note that the failover replica uses synchronous replication. This means that EACH write to primary database will block until the write has been committed and acknowledged on the failover replica. This will introduce high latency to your applications, and it could be significant for systems with a lot of writes.
Clustering Style
In a Tungsten Cluster, a slave is not only a failover candidate, but can be used for reads as well. That 3 node cluster mentioned above already has 3 nodes available for reading, and once again, using the power of the Connector, reads can be automatically directed to slaves without modifying our application! Since the Connector is a true proxy and router, there are quite a few algorithms available for splitting reads and writes. If your application is already read/write aware, great! We can leverage your existing logic. If not, the Connector offers read/write algorithms for you to use.
Also note that by adding more slaves in a Tungsten Cluster, you are scaling the number of nodes available for reads without impacting your application.
Maintenance
With maintenance tasks, you are in control with Tungsten Clustering. Plan your maintenance when you want, and perform many maintenance tasks, like OS patches and MySQL upgrades, with no downtime. Imagine upgrading from MySQL 5.6 to MySQL 5.7 with NO downtime!
RDS/MySQL requires a maintenance window, and during that window, your instances may be restarted. This of course translates to application downtime.
Benefits of a True Cluster
There are many benefits of using Tungsten Clustering. Some of the benefits we discussed are: Automatic failover with no application disconnect, read scaling, read/write splitting, and ease of maintenance. However, there are many more benefits – multi-master (deploy replicated clusters across the continent or across the globe), cloud compatibility (think running a cluster in AWS and being able to failover to Google Cloud!), replication to other databases and data warehouses, and support from engineers with 20-30 years of experience each in databases and clustering!
Click here to talk with us and sign up for a free proof-of-concept!

Comments
Add new comment