This is a follow-up to my previous post, “What is MySQL Data Replication Versus Clustering?”
In that post, we discussed the difference between Replication and Clustering, the two main products we offer here at Continuent.
In this post, we delve into more detail for those who may be just learning about resilient database architecture, or for those who want to know how to achieve business continuity for a mission-critical application without too much overhead - what is database clustering?
Continuent is the leading provider of database clustering for MySQL, MariaDB, and Percona MySQL, enabling mission-critical apps to run on these open source databases globally. Having worked with several Fortune 100 customers and been around a few database “farms,” I feel comfortable discussing what clustering is, and some of the benefits of clustering your database servers.
What Clustering is Not
First of all, let’s breach the subject of what Clustering is not:
- Clustering is not the same as replication. As we distinguished in the previous article mentioned above, clustering includes a layer of replication, but that’s just one part of it. The products are used to solve different problems; please also refer to this blog about the clustering “stack” if you’d like to learn more about all the layers of a database cluster.
- Clustering is not the same as sharding. In our terms at least, every server maintains all the data, not just a “shard” of the data set. However, as with most complex systems, there are exceptions; learn more about scaling with clustering versus sharding in this blog.
Clustering has traditionally been used for NoSQL databases like MongoDB, but it’s more complicated for relational databases like MySQL, MariaDB and Percona Server for MySQL. Nonetheless, these relational databases are widely used for web applications and businesses that require high availability, reliability and performance, as well as geographic scaling. That’s where database clustering comes into play.
What Clustering Is - Simple Terms
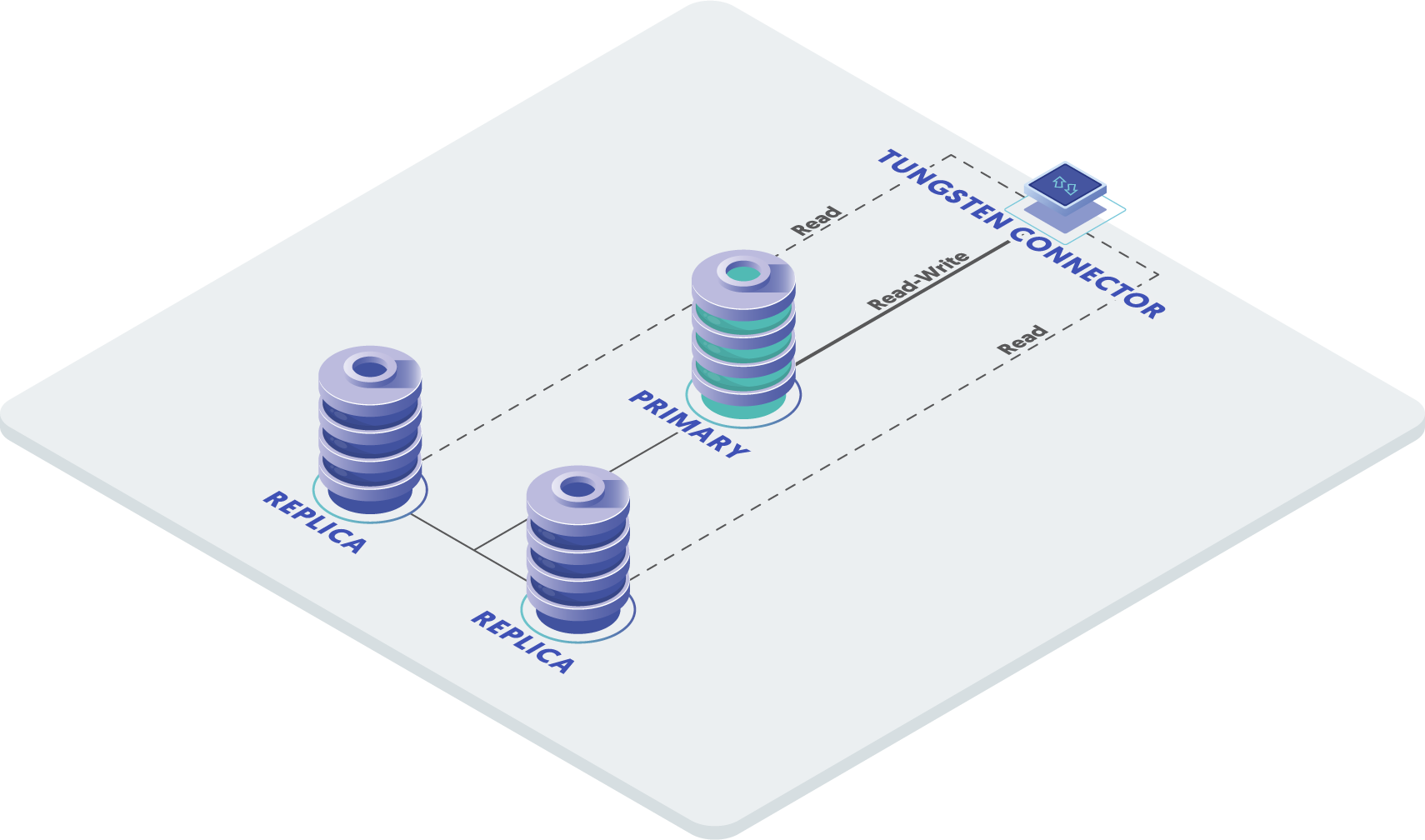
Business-critical and mission-critical applications, such as those developed by Riot Games and VMware, require redundancy and automatic failover that run continuously with little manual intervention and maintenance.
You might be asking - redundancy and automatic failover? These are the primary features of clustering, so let’s take a look:
Redundancy is created by replicating the data to multiple servers, so that there is no single point of failure. These replicas are available to serve the application immediately in the event of a hardware failure or planned maintenance; i.e. through automatic failover, the application starts to communicate with a different server in the cluster, and no manual labor is needed to make the switch.
As you might imagine, database clustering provides a high level of safety and convenience for database operations. However, what happens if all nodes in a cluster go down? For example, what if a natural disaster causes your data center to lose power to your entire cluster? This is where composite clusters come in.
Composite Clusters
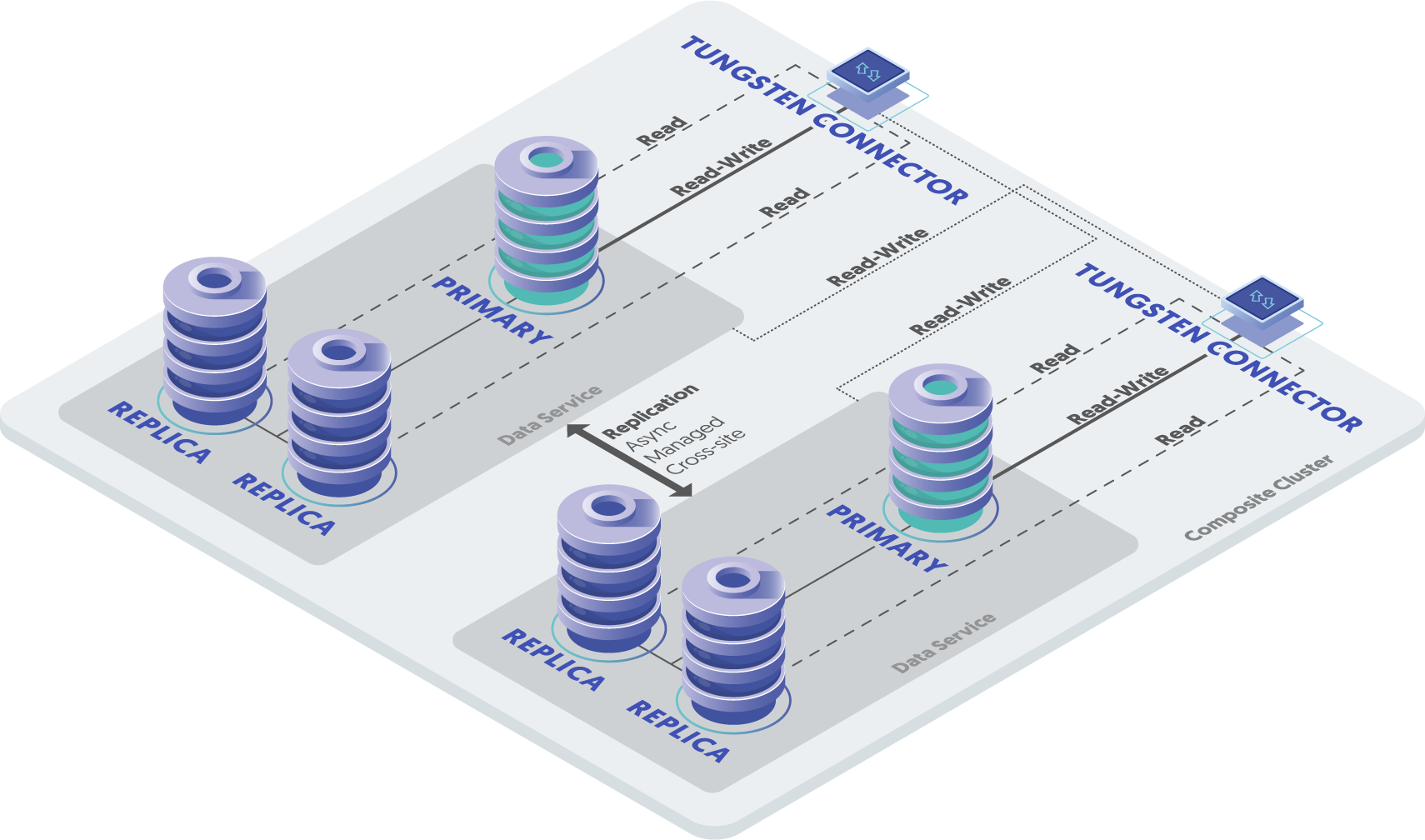
Clusters may contain three nodes organized as a single, standalone cluster, or they may contain multiple clusters with a management layer that makes it easy not only to fail across nodes, but also across whole clusters, data centers, or regions. This can provide geographic business continuity.
A composite cluster contains multiple clusters, and each cluster may be located in a different data center or region of the world to enable disaster recovery (DR). DR provides a level of business continuity that spans geographic limitations, but composite clusters provide greater levels of other database clustering benefits I haven’t mentioned yet, such as performance and cost-effective scalability.
There are two main types of composite database clusters: Multi-Primary or Active/Active (formerly known as multi-master) and traditional Primary-Replica or Active/Passive (formerly known as “master-slave”) clusters. In short, the Primary (formerly called “master”) handles all writes and the Replicas (formerly called “slaves”) handle reads. So Multi-Primary or Active/Active is exactly what it sounds like; more than one server can handle writes. If you’re interested to learn more about composite clusters, please see this blog article. Note that since Continuent released Tungsten v7.0 earlier in 2022, there is now a new composite cluster type called Dynamic Active/Active (DAA), which harnesses benefits of both topologies.
Conclusion
Database clustering can be a great way to improve the performance, availability, and scalability of your mission-critical applications. It provides high availability and failsafe protection against system and data failures.
If you're considering clustering for your MySQL, MariaDB, or Percona Server for MySQL database, be sure to list out your requirements and identify the best solution for your particular needs. Tungsten is designed to be used in a variety of environments, from smaller, local deployments to large scale-out and global infrastructure.
Tungsten Clustering enables organizations to meet the most demanding real-time, high availability, and high-performance requirements by providing support for very large data sets, highly secure data sets (e.g. HIPAA-compliant), and globally-distributed data sets. In addition, an integrated management console (GUI) makes it easy to manage and monitor using Prometheus and Grafana. Tungsten Clustering is a complete, fully-integrated solution that comes with fast expert Support. Reach out to learn more!

Comments
Add new comment