In this blog, we’ll have a quick follow-up (to another blog about cluster-aware replication pipelines) about a Tungsten topology that doesn’t get a lot of attention. Many of our customers love it and it has a few surprising benefits.
A Cluster-Slave topology is one where you have a Tungsten Cluster (any kind - standalone, composite master-slave, composite multi-master, etc.), and you add an external Tungsten Replicator to get the data out, as shown below.
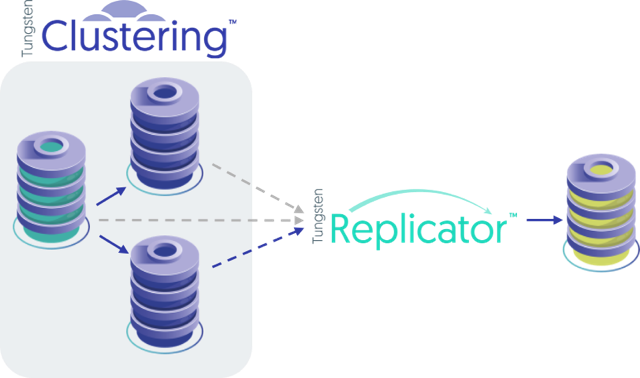
It can be used to replicate data to any of the following targets:
- All MySQL Versions
- Any MySQL version and flavor including MariaDB
- AWS Aurora/RDS (including cross-region), Azure SQL, and GCP SQL
- Redshift
- Hadoop (all major distributions)
- Kafka
- MongoDB (now including Atlas!)
- Oracle
- PostgreSQL
- Clickhouse (experimental)
- Vertica
The Cluster-Slave is an easy way to have automated real-time replication to various targets (much more reliable than ETL) with features that make it ideal for big data analytics, reporting, and backups. Some benefits include:
- Simplicity - OLTP and OLAP systems using a single technology that is infinitely scalable. Tungsten Replicator is Tungsten Cluster-aware - even if your master fails over for any reason, the cluster-slave will continue to operate without any reconfiguration required. This is because continuity is the bread and butter of Continuent, and the design at the replication-level uses the highly-portable THL (Transaction History Log).
- Flexibility - Tungsten is comprised of highly configurable Java processes that open doors to achieve multi-cloud, hybrid cloud, and other cutting-edge cross-platform and cross-vendor models
- Performance - run queries on the Cluster-Slave to reduce load on the main database cluster, so your application can perform at its absolute best.
- Data Safety and Resilience - Having this replica of the data external to the cluster is an extra failsafe (not as much of a failsafe as if it were another cluster, such as with multi-site composite clustering or multi-master clustering, but it is another copy nonetheless).
- Security - Easily filter and customize the data going to the Cluster-Slave, for specific purposes. Also, a separate datasource external to your main cluster can be used to isolate certain users (ie. developers) outside of the main cluster.
Besides these benefits, customers get peace of mind from Continuent's 24/7 enterprise-grade support with response times (typically 5 minutes). So how do you get started? To build one of these is simple, and besides the Docs you can find more details in this blog. I used Ansible to set up my first Cluster-Slave on CentOS 7 and MySQL 5.7 running on Amazon EC2 instances:
- Fire up an EC2 instance. Note that you can choose basically any Linux for the OS. For my first setup, I chose T2-medium instances with 8GB of RAM, a pretty typical size. Configure this node to connect to the cluster members through SSH.
- Using the Ansible repo on Github, prep the node. Give the Cluster-Slave node a standard cluster-slave tungsten.ini (it looks like a Tungsten Replicator applier INI and is shown here).
- Let Ansible install MySQL and Tungsten.
Whether you weren’t aware of the Cluster-Slave Topology or were curious to learn more about it, I hope this blog helped. Please reach out if you have any questions or would like help getting set up!

Comments
Add new comment