Now just over 10 years old, Apache Kafka was initially released in January 2011 by its original author(s) at LinkedIn - and quickly open sourced following that initial release. It is still open source today and looked after by the developers of the Apache Software Foundation.
For those not yet familiar with it, Apache Kafka is a highly scalable messaging platform that provides a method for distributing information through a series of messages organised by a specified topic. Written in Scala and Java, it aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. It is still used to perform numerous real-time services across all of LinkedIn. Other example applications include managing passenger and driver matching at Uber, providing real-time analytics and predictive maintenance for British Gas smart home and plenty more.
Today, Apache Kafka can be found in over 80% of all Fortune 100 companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Replication Between MySQL & Kafka
Replication allows the movement of data from the source database(s) to target database(s) in real time, keeping the target in sync with the source.
In the case of Kafka, Tungsten Replicator posts data changes as messages to Kafka Topics which can be subscribed to, and processed by any compatible consumer, providing flexibility to utilise the data however your business requires.
Tungsten Replicator (AMI) for Kafka
Tungsten Replicator provides high-performance and improved replication functionality over the native MySQL replication solution and into a range of targets / databases, such as Kafka of course… as well as MySQL (all versions), Oracle, Vertica, AWS RedShift, ClickHouse, Hadoop, MongoDB & PostgreSQL.
It is the most advanced heterogeneous replication solution for MySQL, MariaDB & Percona Server, including Amazon RDS MySQL and Amazon Aurora. It’s available as an AMI and can be accessed via AWS.
How Replication to Kafka Works
As seen above, Apache Kafka is a highly scalable messaging platform that provides a method for distributing information through a series of messages organised by a specified topic.
With Tungsten Replicator (AMI) the incoming stream of data from the upstream replicator is converted, on a row by row basis, into a JSON document that contains the row information. A new message is created for each row, even from multiple-row transactions.
Option 1: Local Install
The extractor reads directly from the logs, even when the DBMS service is down. This is the default.
Option 2: Remote Install
The extractor gets log data via MySQL Replication protocols (which requires the DBMS service to be online). This is how we handle Amazon Aurora extraction tasks.
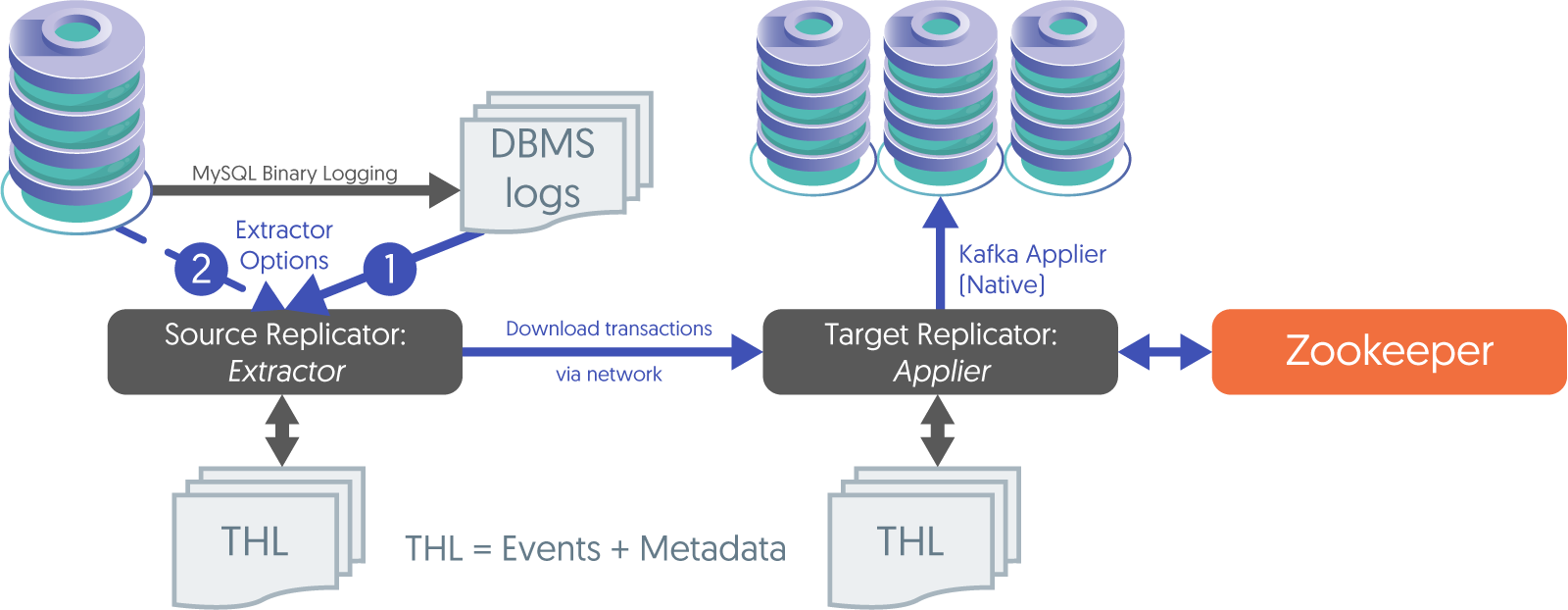
What Tungsten Replicator Does to Apply into Kafka
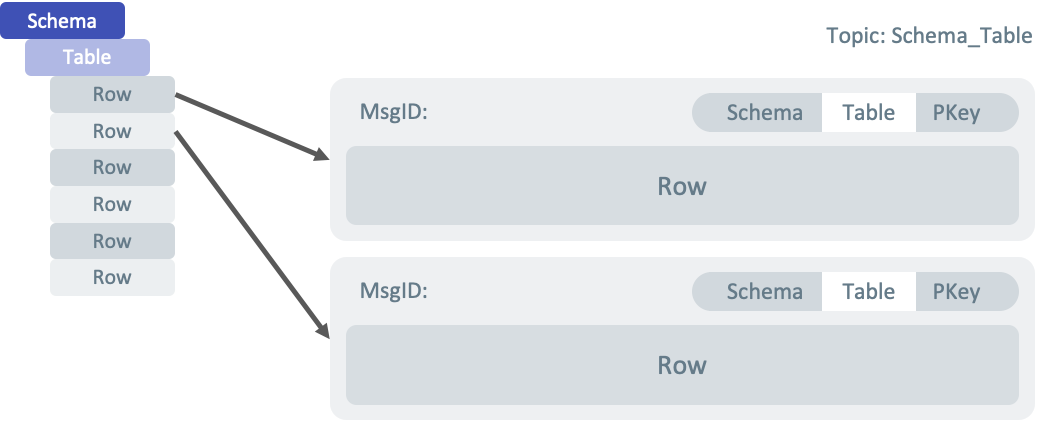
Tungsten Replicator takes an incoming row and converts it to a message, which consists of metadata as follows:
- Schema name, table name
- Sequence number
- Commit timestamp
- Operation Type
- Embedded Message Content
See what the message structure looks like in the example below.
Message Structure
Note (I) - Zookeeper
This AMI supports replication into Apache Kafka only, and requires a running Zookeeper instance.
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
To learn more about it, see the Zookeeper Wiki: https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
Note (II) - Preparing for Kafka Replication
For more detailed information on how to best prepare for Kafka replication, see our docs here: https://docs.continuent.com/tungsten-replicator-5.3/deployment-kafka-preparation.html
How the Tungsten Replicator Can Be Used
Generally speaking, any application which uses Kafka can benefit.
Kafka isn't persistent so there is no data store, and hence any kind of application which handles that kind of flow of "status" update type data can benefit here. It could also potentially increase the reach as there are Kafka consumers which could feed into other persistent data stores that Tungsten Replicator doesn’t write directly into itself.
Let us know about your own replication needs or use cases … and check out the details below in order to experience the Tungsten Replicator (AMI) yourselves!
How to Get Started With the Tungsten Replicator AMI
Getting started with the 14-Day free trial
Users can try one instance of each type of the AMI for free for 14 days to get them started (AWS infrastructure charges still apply).

Please note that free trials will automatically convert to a paid hourly subscription upon expiration and the following then applies in the case of Kafka targets.
Replicate from AWS Aurora, AWS RDS MySQL, MySQL, MariaDB & Percona Server to Kafka from as little as $0.40/hour
With Tungsten Replicator (AMI) on AWS, users can replicate GB's of data from as little as $40c/hour:
- Go to the AWS Marketplace, and search for Tungsten, or click here.
- Choose and Subscribe to the Tungsten Replicator for MySQL Source Extraction.
- Choose and Subscribe to the target Tungsten Replicator AMI of your choice.
- Pay by the hour.
- When launched, the host will have all the prerequisites in place and a simple "wizard" runs on first launch and asks the user questions about the source and/or target and then configures it all for them.
Watch the Getting Started Walkthrough
Our colleague Chris Parker recorded this handy walk-through on how to get started with the Tungsten Replicator AMI if you need some tips & tricks.

Extraction and Appliers
Below you’ll find the full listing of extractors and appliers that are available with Tungsten Replicator.
Replication Extraction from Operational Databases
- MySQL (all versions, on-premises and in the cloud)
- MariaDB (all versions, on-premises and in the cloud)
- Percona Server (all versions, on-premises and in the cloud)
- AWS Aurora
- AWS RDS MySQL
- Azure MySQL
- Google Cloud SQL
Available Replication Target Databases
Do give Tungsten Replicator AMI a try and let us know how you get on or if you have any questions by commenting below!
Related Blogs
Check out our related blogs if you’re (also) working with these databases / platforms:

Comments
Add new comment